데이터 전처리란 무엇인가? AI 학습의 시작

인공지능을 위한 첫걸음, 데이터를 다듬는 기술
AI의 시대, 데이터는 새로운 연료라고 불릴 만큼 그 중요성이 점점 커지고 있습니다. 하지만 아무리 많은 데이터가 있더라도 정제되지 않은 정보는 제대로 된 결과를 만들어내기 어렵습니다. 이 때문에 우리는 데이터 전처리라는 과정을 통해 데이터를 정돈하고 분석 가능한 형태로 바꾸게 됩니다. 데이터 전처리는 말 그대로 데이터를 사용하기 좋게 가공하는 작업입니다. 이 과정은 AI 모델이 학습하기 전에 반드시 선행되어야 하며, 최종 결과의 품질에도 큰 영향을 미칩니다. 많은 분들이 'AI는 자동으로 알아서 다 해주는 거 아닌가요?'라고 생각하시지만, 실제로는 그렇지 않습니다. 우리가 직접 데이터를 세심하게 다듬고 정리해야 제대로 된 결과를 기대할 수 있습니다. 오늘은 이 데이터 전처리라는 개념이 무엇인지, 어떤 단계로 진행되는지, 그리고 왜 중요한지를 쉽게 풀어보도록 하겠습니다.
| 데이터 전처리 | AI 학습 전 데이터를 정리하는 필수 과정 |
| 왜 중요한가? | 결과의 정확도와 성능에 직접적인 영향을 줌 |
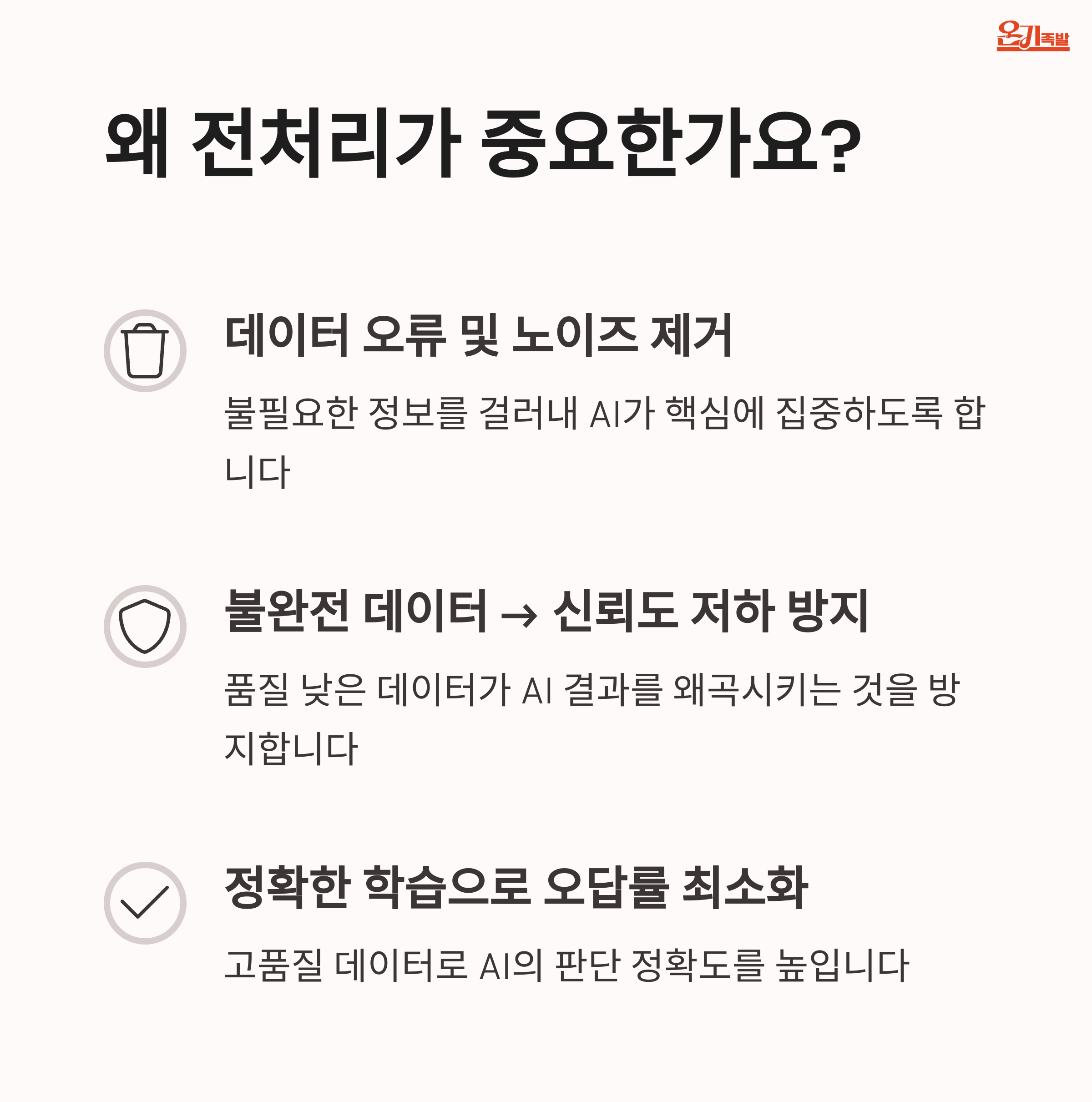
데이터 전처리는 단순히 데이터를 정리하는 것을 넘어, AI 모델이 정확한 판단을 내릴 수 있도록 돕는 기반 작업입니다. 예를 들어 누락된 값을 채우거나, 이상치를 제거하고, 텍스트 데이터를 숫자로 변환하는 등 다양한 작업이 포함됩니다. 이러한 과정은 모델이 데이터를 오해하지 않도록 하는 중요한 역할을 하며, 전처리가 잘 된 데이터는 훨씬 더 안정적이고 일관된 결과를 도출합니다. 결국, 데이터 전처리는 AI 성능을 좌우하는 핵심 요소라고 볼 수 있습니다.
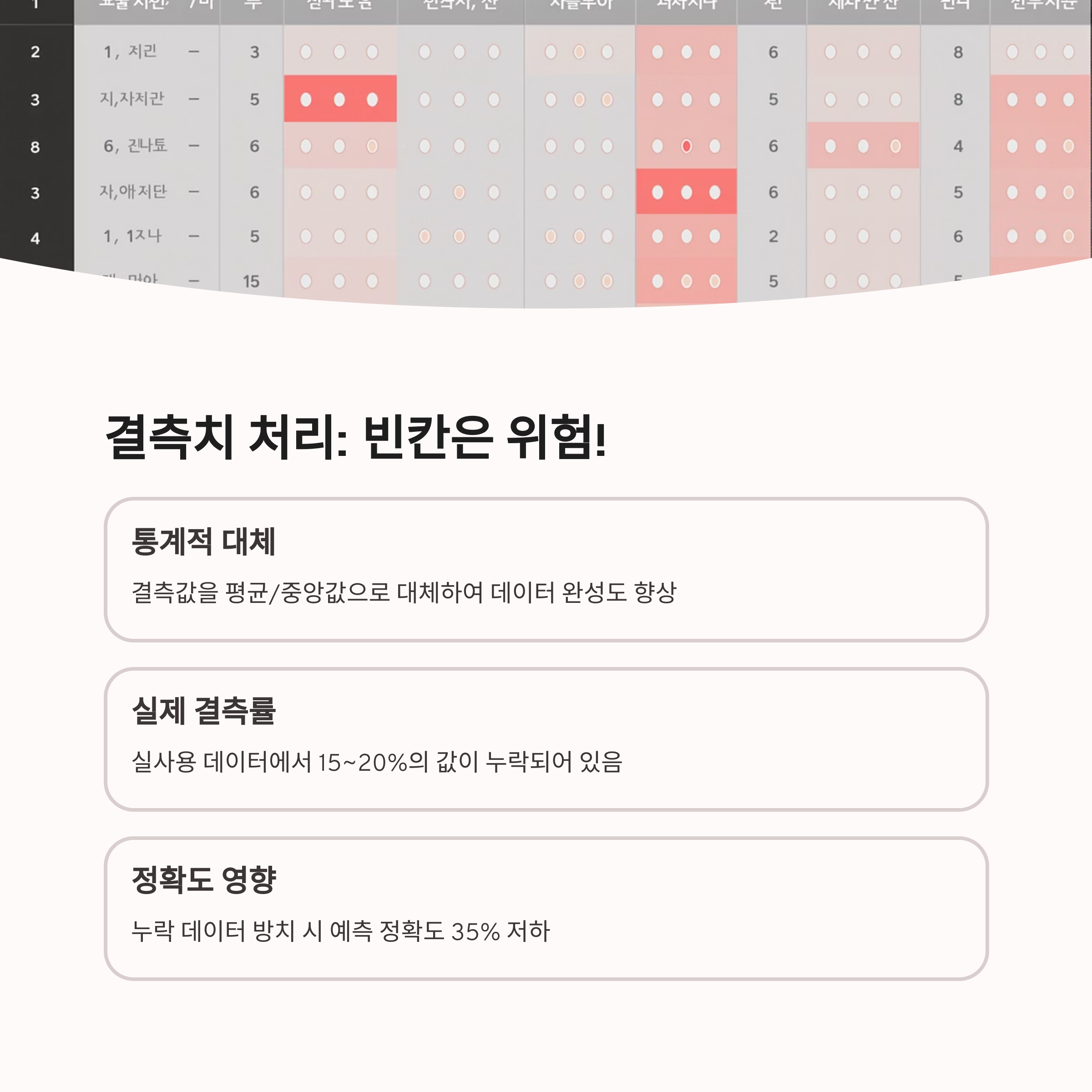
많은 초보 개발자들은 모델 구축에만 집중하는 경향이 있지만, 실제로 프로젝트 성공의 절반 이상은 전처리 단계에서 결정됩니다. 예를 들어, 고객 리뷰를 분석하는 프로젝트라면 오타 교정, 중복 제거, 감정 단어 정규화 등의 작업이 필수적입니다. 이런 작업을 생략하면 모델이 잘못된 방향으로 학습하거나, 결과가 왜곡될 수 있습니다. 따라서 전처리 단계는 단순한 정리 작업이 아니라 데이터에 생명을 불어넣는 과정이라 할 수 있습니다.

전처리의 핵심은 데이터의 질을 높이는 데 있습니다. AI는 데이터를 기반으로 판단하기 때문에, 입력이 부정확하면 출력도 신뢰할 수 없습니다. 따라서 결측값 처리, 표준화, 이상치 제거 등은 꼭 거쳐야 할 단계입니다. 좋은 데이터를 만드는 것이 곧 좋은 AI를 만드는 길이며, 전처리는 그 시작이자 끝이라 해도 과언이 아닙니다.
| 결측값 처리 | 이상치 제거 | 표준화 |
| 누락된 데이터를 평균값 등으로 채우는 작업 | 비정상적으로 벗어난 데이터를 제거 | 데이터 단위를 맞춰 비교 가능하게 만드는 과정 |
| 결측값이 많을 경우에는 행 삭제도 고려 | Z-score, IQR 등의 방법을 사용 | Min-Max, Z-score 정규화 기법 사용 |

AI 학습에서 데이터 전처리는 단순한 선택이 아니라 필수입니다. 제대로 된 데이터 없이는 아무리 훌륭한 모델도 빛을 발할 수 없습니다. 전처리는 그만큼 기본이자 핵심이며, 이 단계를 충실히 수행할수록 더 정확하고 의미 있는 결과를 만들 수 있습니다. 데이터를 수집했다면, 그다음은 반드시 '정리'입니다. 그 정리의 첫 단추가 바로 데이터 전처리이며, 이 과정을 소홀히 한다면 AI 프로젝트의 성공도 어려워집니다. 지금부터라도 데이터 전처리에 대해 더 깊이 이해하고, 실무에 적용해 보시길 바랍니다.

여러분의 의견을 들려주세요!
이 글이 도움이 되셨나요? 데이터 전처리에 대해 더 알고 싶은 부분이나 실무에서 겪으신 경험이 있다면 댓글로 나눠주세요. 함께 배우고 성장하는 공간이 되었으면 좋겠습니다!
태그: